
数据结构算法与算法分析
转载于崽🐏的小屋
数据结构算法与算法分析
算法
算法定义
解决问题的方法和步骤。在计算机中表现为指令的有限序列。其中每条指令表示一个或多个操作。
算法的描述
自然语言;流程图【NS图、框图】;伪代码(类C语言);程序设计(C、Java…)
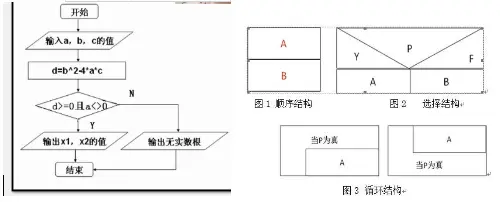
类C语言介于伪码语言和程序设计语言之间的一种表示形式,保留了C语言的精华,不拘泥于C语言的语法细节,同时也添加了一些C++的成分。
特点:便于理解,阅读能方便地转换成C语言。
程序与算法
程序=数据结构+算法
数据结构通过算法来实现操作
算法根据数据结构来实现操作
算法的特性(确定、有穷、可行、输入、输出)
有穷性:算法在执行有限步骤之后,自动结束而不会出现无限循环,并且每一个步骤都在可接受的时间范围内完成。当然这里的有穷并不是纯数学意义的,而是在实际应用中合理的、可以接受的“边界”。你说你写一个算法,计算机需要算上20年,一定会结束,他在数学上是有穷的,媳妇都熬成婆了,算法的意义就不大了。确定性:算法的每一个步骤都有确定的含义,不会出现二义性(不会有歧义)。可行性:算法中的所有操作都可以通过已经实现的基本操作运算执行有限次来实现。输入:一个算法有零个或多个输入。当用函数描述算法时,输入往往是通过形参表示的,在它们被调用时,从主调函数获得输入值。输出:一个算法有一个或多个输出,它们是算法进行信息加工后得到的结果,无输出的算法没有任何意义。当用函数描述算法时,输出多用返回值或引用类型的形参表示。
算法的设计要求
好的算法应该具有正确性、可读性、健壮性、时间效率高和存储量低的特征。
正确性(Correctness):能正确地反映问题的需求,能得到正确的答案。分以下四个层次:
- 算法程序没有语法错误;
- 算法程序对n组输入产生正确的结果;
- 算法程序对典型、苛刻、有刁难性的几组输入可以产生正确的结果;
- 算法程序对所有输入产生正确的结果;
但我们不可能逐一的验证所有的输入,因此算法的正确性在大多数情况下都不可能用程序证明,而是用数学方法证明。所以一般情况下我们把层次3作为算法是否正确的标准。
可读性(Readability):算法,首先应便于人们理解和相互交流,其次才是机器可执行性。可读性强的算法有助于人们对算法的理解,而难懂的算法易于隐藏错误,且难于调试和修改。健壮性(Robustness):当输入的数据非法时,好的算法能适当地做出正确反应或进行相应处理,而不会产生一些莫名其妙的输出结果。【健壮性又叫又名鲁棒性即使用棒子粗鲁地对待他也可以执行类似于Java预料到可能出现的异常并对其进行捕获处理】高效性(Efficiency):时间效率高和存储量低
算法分析
算法分析
算法分析的目的是看算法实际是否可行,并在同一问题存在多个算法时可进行性能上的比较,以便从中挑选出比较优的算法。
(时间效率)运行时间的长短和(空间效率)占用内存空间的大小是衡量算法好坏的重要因素。
衡量算法时间效率的方法主要有两类:事后统计法和事前分析估算法。
事后统计法需要先将算法实现,然后测算其时间和空间开销。这种方法的缺陷很显然,一是必须把算法转换成可执行的程序,如果编辑出来发现它根本是很糟的算法,不是竹篮打水一场空吗?二是时空开销的测算结果依赖于计算机的软硬件等环境因素,这容易掩盖算法本身的优劣。三是算法的测试数据设计困难,并且程序的运行时间往往还与测试数据的规模有很大关系,效率高的算法在小的测试数据面前往往得不到体现。比如10个数字的排序,不管用什么算法,差异几乎是零。而如果有一百万个随机数字排序,那不同算法的差异就非常大了。那么我们为了比较算法,到底用多少数据来测试,这是很难判断的问题。所以我们通常采用事前分析估算法。
一个算法的执行时间大致上等于其所有语句执行时间的总和,而语句的执行时间则为该条语句的重复执行次数和执行一次所需时间的乘积。一条语句的重复执行次数称作语句频度(FrequencyCount)。语句的执行要由源程序经编译程序翻译成目标代码,目标代码经装配再执行,因此语句执行一次实际所需的具体时间是与机器的软、硬件环境(如机器速度、编译程序质量等)密切相关的。设每条语句执行一次所需的时间均是单位时间,则一个算法的执行时间可用该算法中所有语句频度之和来度量。所谓的算法分析并非精确统计算法实际执行所需时间,而是针对算法中语句的执行次数做出估计,从中得到算法执行时间的信息。
1 | for (int i = 1; i <= n; i++) { //频度为n+1 |
【i从1~n首先判断条件是否成立,条件满足执行循环体并i++,i=n+1判断条件是否成立条件不满足,退出循环,判断n+1次循环体执行了n次】
该算法中所有语句频度之和,是矩阵阶数$n$的函数,用$f(n)$表示之。换句话说,上例算法的执行时间与$(n)$成正比。
$f(n)=2n^3+3n^2+2n+1$
练习
1 | x = 0; |
渐进时间复杂度
渐进时间复杂度
对于稍微复杂一些的算法,计算出算法中所有语句的频度通常是比较困难的。通常,算法的执行时间是随问题规模增长而增长的,因此对算法的评价通常只需考虑其随问题规模增长的趋势。这种情况下,我们只需要考虑当问题规模充分大时,算法中基本语句的执行次数在渐近意义下的阶。
1 | for (int i = 1; i <= n; i++) { //频度为n+1 |
$f(n)=2n^3+3n^2+2n+1$
$lim_{n \to \infty}f(n)/n^3=lim_{n \to \infty}\frac{(2n^3+3n^2+2n+1)}{n^3}=2$
即当$n$足够大时,$f(n)$和$n^3$之比是一个不等于0的常数。即$f(n)$和$n^3$是同阶的,或者说$f(n)$和$n^3$的数量级(Orders of Magnitude)相同。在这里我们用”O”来表示数量级,记作$T(n)=O(f(n))=O(n^3)$。由此我们可以给出下述算法时间复杂度的定义。
一般情况下,算法中基本语句重复执行的次数是问题规模$n$的某个函数$f(n)$,算法的时间量度记作 $$T(n)=O(f(n))$$
它表示随问题规模$n$的增大,算法执行时间的增长率和$f(n)$的增长率相同,称作算法的渐进时间复杂度,简称时间复杂度(Time Complexity)。
基本语句:执行次数最多;对算法运行时间贡献最大;嵌套最深的语句。
分析算法时间复杂度的基本方法
找出语句频度最大的那条语句作为基本语句;
计算基本语句的频度,得到问题规模n的某一个函数;
取其数量级用O表示
定理:若$f(n)=a_mn^m+a_{m-1}n^{m-1}+\cdots+a_1n+a_0$是一个$m$次多项式,则$T(n)=O(n^m)$。
忽略所有低次幂项和最高次幂的系数,这样可以简化算法分析,也体现出了增长率的含义。
1 | void exam(float x[][], int m, int n) { |
常数阶
1 | for (int i = 0; i < 10000; i++) { |
实际上,如果算法的执行时间不随问题规模n的增加而增长,算法中语句频度就是某个常数。即使这个常数再大,算法的时间复杂度都是$O(1)$。
线性阶
给崽羊一个长度为10cm的面包,崽羊每三分钟吃掉1cm,那么他吃掉整个面包要多久?
答案自然是$3 \times 10=30$min
如果面包的长度为$n$cm呢?
此时吃掉整个面包需要$3 \times n$即$3n$分钟。
如果用一个函数来表达吃掉整个面包所需要的时间可以记作$T(n)=3n$
对数阶
给崽羊一个长度为16cm的面包,崽羊每5min吃掉面包剩余长度的一半,第1min吃掉8cm,第2min吃掉4cm,第3min吃掉2cm……那么崽羊把面包吃得只剩下1cm,需要多少天呢?
这个问题翻译一下,就是数字16不断地除以2,除几次以后的结果等于1?这里要涉及到数学当中的对数,以2位底,16的对数,可以简写为$\log_216$。
因此,把面包吃得只剩下1cm,需要 $5 \times log_216=5 \times 4=20$ min
如果面包的长度为$n$cm呢?
此时吃掉整个面包需要$5 \times log_2n$分钟记作$T(n)=5 \times log_2n$
1 | i = 1; |
若循环执行1次:$i=1 \times 2=2$,
若循环执行2次:$i=2 \times 2=2^2$,
若循环执行3次:$i=2^2 \times 2=2^3$,
$\cdots$,
若语句$i=i \ast 2$执行次数为$x$,由循环条件得$i \leq n$,∴ $2^x \leq n$,∴ $x \leq \log_2n$
平方阶
1 | int i, j, count = 0; |
由于当$i=0$时内循环执行$n$次,当$i=1$时内循环执行$n-1$次,$\cdots$ ,当$i=n-1$时内循环执行$1$次总执行次数
$n+(n-1)+(n-2)+\cdots+1=\frac{n(n+1)}{2}$
时间复杂度是$O(n^2)$
立方阶
1 | x = 1; |
显而易见,该程序段中频度最大的语句是x++;,这条最深层循环内的基本语句的频度,依赖于各层循环变量的取值,由内向外可分析出语句x++;的执行次数为:$$\displaystyle \sum_{i=1}^{n}\displaystyle \sum_{j=1}^{i}\displaystyle \sum_{k=1}^{j}1=\displaystyle \sum_{i=1}^{n}\displaystyle \sum_{j=1}^{i}j=\displaystyle \sum_{i=1}^{n}\frac{i(i+1)}{2}=\frac12(\displaystyle \sum_{i=1}^{n}i^2+\displaystyle \sum_{i=1}^{n}i)=\frac12(\frac{n(n+1)(2n+1)}6+\frac{n(n+1)}2)=\frac{n(n+1)(n+2)}6$$
最好、最坏和平均时间复杂度
有的情况算法的基本操作重复执行的次数还随问题输入的数据集不同而不同
例:顺序查找,在数组a[i]中查找值等于$e$的元素,返回其所在位置。
1 | for (int i = 0; i < n; i++) { |
最好的情况$a_0=e$执行$1$次
最坏数组中没有$e$或$an-1=e$执行$n$次
而对于一个算法来说,需要考虑各种可能出现的情况,以及每一种情况出现的概率,一般情况下,可假设待查找的元素在数组中所有位置上出现的可能性均相同。类似于数学中求期望值。计算每一种情况执行次数与概率的乘积在求和。
最坏时间复杂度是指在最坏情况下算法的的复杂度;
最好时间复杂度是指在最好情况下算法的的复杂度;
平均时间复杂度是指算法在所有可能情况下,按照输入实例以等概率出现时,算法计算量的加权平均值。
通常考虑最坏和平均但有时平均比较难计算只考虑最坏时间复杂度,最坏情况运行时间是一种保证,那就是运行时间不会再坏了。
计算公式
对于复杂的算法,可以将它分成几个容易估算的部分,然后利用大O加法法则和乘法法则,计算时间复杂度:
- 加法法则:$T(n)=T_1(n)+T_2(n)=O(f(n))+O(g(n))=O(max(f(n),g(n)))$
- 乘法法则:$T(n)=T_1(n) \times T_2(n)=O(f(n)) \times O(g(n))=O(f(n) \times g(n))$
| $n$ | $f(1)$ | $f(log_2n)$ | $f(n)$ | $f(nlog_2n)$ | $f(n^2)$ | $f(n^3)$ | $f(2^n)$ | $f(n!)$ |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 2 | 1 |
| 2 | 1 | 1 | 2 | 2 | 4 | 8 | 4 | 2 |
| 4 | 1 | 2 | 4 | 8 | 16 | 64 | 16 | 24 |
| 8 | 1 | 3 | 8 | 24 | 64 | 512 | 256 | 40320 |
| 16 | 1 | 4 | 16 | 64 | 256 | 4096 | 65536 | 2.09E+13 |
| 32 | 1 | 5 | 32 | 160 | 1024 | 32768 | 4.29E+09 | 2.63E+35 |
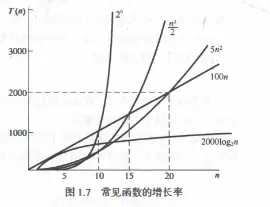
常见的时间复杂度按数量级递增排列依次为:常量阶$O(1)$、对数阶$O(log_2n)$、线性阶$O(n)$、线性对数阶$O(nlog_2n)$、平方阶$O(n^2)$、立方阶$O(n^3)$、$\cdots$ 、$k$次方阶$O(n^k)$、指数阶$O(2^n)$等。
如果时间复杂度是平方阶最好降低到对数阶实在不行平方阶也可以接受,立方阶也尚可。
算法的空间复杂度:算法要占据的空间
算法本身要占据的空间:输入/输出、指令、常数、变量等。
算法要使用的辅助空间。
若输入数据所占据的空间只取决于问题本身和算法无关,这样只需分析该算法在实现时所需的辅助单元即可,若算法执行时所需的辅助单元相对于输入数据量而言是个常数,则称此算法为原地施工,空间复杂度为$O(1)$
例:数组逆序,将一维数组$a$中的$n$个数逆序存放到原数组中
1 | //算法1 |
算法1仅需要另外借助一个变量$t$,与问题规模$n$大小无关,所以其空间复杂度为$O(1)$
算法2需要另外借助一个大小为$n$的辅助数组$b$,所以其空间复杂度为$O(n)$
时间与空间的取舍
人们之所以花大力气去评估算法的时间复杂度和空间复杂度,其根本原因是计算机的运算速度和空间资源是有限的。就如一个大财主,基本不必为日常的花销而伤脑筋,而一个没有多少积蓄的普通人则不得不为日常的花销精打细算。对于计算机系统来说也是如此,虽然目前计算机的CPU处理速度不断飙升,内存和硬盘空间也越来越大,但是面对庞大而复杂的数据和业务,我们仍要精打细算,选择最有效的利用方式。
举个例子说,要判断某年是不是闰年,你可能会花一点心思来写一个算法,每给一个年份,就可以通过这个算法计算得到是否闰年的结果。
另外一种方法是,事先建立一个有2050个元素的数组,然后把所有的年份按下标的数字对应,如果是闰年,则此数组元素的值是1,如果不是元素的值则为0。这样,所谓的判断某一年是否为闰年就变成了查找这个数组某一个元素的值的问题。
第一种方法相比起第二种来说很明显非常节省空间,但每一次查询都需要经过一系列的计算才能知道是否为闰年。第二种方法虽然需要在内存里存储2050个元素的数组,但是每次查询只需要一次索引判断即可。
这就是通过一笔空间上的开销来换取计算时间开销的小技巧。到底哪一种方法好?其实还是要看你用在什么地方。
但在绝大多数情况下,时间复杂度更重要一些,我们宁愿多分配一些内存空间也要提升程序的执行速度。
